Python-基础语法笔记
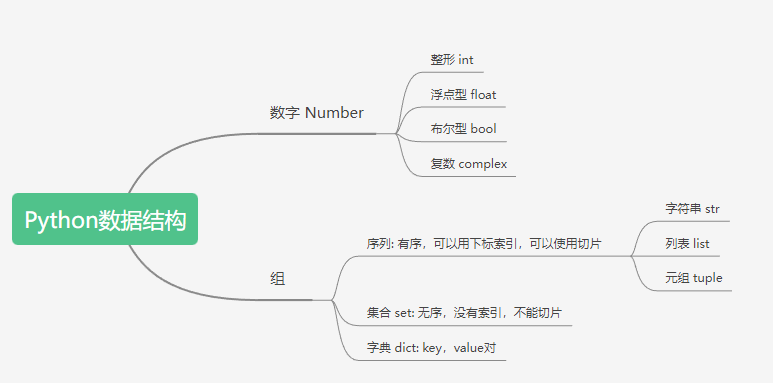
Python基本数据类型
int, str, tuple是值类型(不可改变)
list, set, dict是引用类型(可变)
id()函数可以查看数据地址位置
变量和对象
对象的三个特征:值、身份、类型(value/id/type)
变量值的判断:==
变量身份的判断:is
变量类型的判断:isinstance()
包和模块
结构
python工程的组织结构:包、模块、类
- 包:最顶级的组织结构(文件夹)
- 模块: 文件(.py文件)
- 类:包含了函数、变量(两个属于类本身的特性)
- 包的名字- 文件夹的名字
- 模块的名字- 文件的名字
- 命名空间(路径):包名.模块名
- Python区分普通文件夹与包:包里面包含一个特殊的文件_init_.py
__init__.py的路径就是包名
import导入方法
import xxx
import 引入的是模块
import 包名.模块名from xxx import
from import 引入的是变量(也可以引入模块,不常用)
from 包名.模块名 import 变量名from demo1.c1 import a
引入demo1.c1模块下的a变量from demo1.c1 import *
1)引入模块下所有变量
2)* 对应引用模块中的__all__
__all__可以指定部分变量,故也可以通过*引入部分指定的变量
init.py的作用
- 当包被导入(import)的时候,python会首先自动执行__init__.py文件
- 导入包中的模块或模块的变量,也会先运行__init__.py文件
- 具体应用1:在__init___.py中使用__all__[‘模块1’,’模块2’]来限定导入包时,使用*只能导入模块1和模块2的内容
- 在__init__.py中批量引用系统库,则import包后即可使用这些库
__init__.py的文件的文件名就是包名
包和模块是不会被重复导入的
避免循环导入
模块内置变量
dir()函数可以返回模块中所有变量,包括自己定义的变量与系统内置变量,其中系统内置变量一般会是“__变量__”格式
内置变量:
1 | |
入口文件 以及 __name__运用
入口文件的定义:主动运行的那个主文件就叫做入口文件,其它在此文件中引用的称为模块
如果一个.py文件被当做应用文件入口(入口文件),则其内置函数反应如下:
__name__:__main__(不是模块名)
__package__:NoneType,即被视作不属于任何包
__doc__:根据有无注释决定
__file__:与python的文件存储有关
if __name__ == '__main__'判断是入口文件,还是一般模块,当程序作为入口文件时会被执行
python -m 包名.模块名,可以把文件当做普通模块来运行(不能在python文件所在文件夹执行),普通模块必须有包
相对导入和绝对导入
- 顶级包与入口文件main.py(可执行文件)的位置有关,与入口文件main.py同级的就是该包下所有模块的顶级包,入口文件不存在顶级包的概念。
- 绝对导入是从顶级包到被导入模块的一个完整路径
- 相对导入,一个‘.’表示前一个包,两个’..’表示上一级包,‘…’表示上上级包,以此类推。
- import 不支持相对导入,只能使用from import 实现相对导入
- 使用相对路径导入不能超过顶级包
- 入口文件不能使用相对路径
原因:相对路径可以找到模块机制->根据内置模块变量__name__定位,main 文件是入口文件–>执行时main的__name__会被 python 强行改成__main__(__main__这个模块是不存在的),所以入口文件用绝对路径,如果一定要用相对导入,可以将入口模式作为一个模块来执行.
函数
return语句
- return可以返回任何类型的数据
- 多个结果的返回,返回的是元组
- 返回的结果提取 最好用序列解包的方式(有利于之后的维护)
序列解包
1 | |
以上都称为序列解包
不限于列表和元组,而是适用于任意序列类型(甚至包括字符串和字节序列)
要求:赋值运算符左边的变量数目与序列中的元素数目相等
函数参数
必须参数:函数的参数列表中定义的必须赋值的参数,在函数调用的时候必须要给其赋值。
形参:定义函数的时候所用到参数式形参,如def add(x,y),其中,x,y就是形参。
实参:函数调用的时候所用到的参数,如add(1,2),1和2就是实参。关键字参数:在函数调用时明确指出实参时赋值给那个形参的,可以不考虑形参中的顺序,更加方便、便于理解、便于记忆
如 c=add(y=1,x=2)
注:定义几个参数,就要传递多少个参数默认参数:在定义函数时,对形式参数直接赋值,即称为默认参数。
参数列表 默认参数必须在非默认参数的后面,否则会报错; 在调用的时候,非默认参数的传递也不能在默认参数后面,和定义的时候相同可变参数:
- 调用时可传入多个实参,返回的结果是tuple类型
- 方式为def demo(参数)(即在参数前面加号)
- 调用时如果实参为元组tuple,则返回的会是二维元组
调用:a=(1,2,3,4,5,6)
demo(a)
返回:((1, 2, 3, 4, 5, 6),) - 如何解组,方法是调用时在元组实参前也加*
调用:demo(*a)
返回:(1,2,3,4,5,6) - 可变函数可以与必须参数、默认参数一起使用
- 形参没法跳过默认参数,所以默认函数建议放在最后
def demo(“a”, 1,2,3, para2 = “para”) - 经验指明,形参不要设计太多种类
关键字可变参数
形式:**参数,**表明是关键字可变参数,此时其输出的类型为字典dict
遍历字典类型数据方法: for key,value in param.items():
无论是普通可变参数还是关键字可变参数,都是为了简化函数调用,在调用是平铺输入数据
变量作用域
- 全局变量
全局变量是作用于整个模块下的 - 局部变量
函数内部的变量是局部变量,只作用于函数内,函数外调用无效 - python没有块级作用域
- 函数内部的for in语句等并不能形成一个块级作用域
- for in语句内部的变量与函数内部的局部变量同级
- 作用域具有逐层引用的链式特性
- global关键字可以让局部变量变成全局变量
面向对象:类
类的作用:
- 用于封装一系列的变量和函数;类最基本的作用就是封装;
- 在一个模块内可以定义很多个类。模块–类–函数,这是一个比较清晰的结构;
- 类下面的函数一般称为”方法”;
- 类只负责定义或刻画或描述某些东西,但不负责执行代码;所以在类内部用函数调用方式来执行是行不通的;
- 建议一个模块里只写各种类,而把执行放到另一个模块里去。
在类里编写函数与在模块内编写函数是有一些区别的:
- 对于实例方法,必须强制在类里的函数定义中括号内显示加上self;
- 类里函数体外的变量不能理解为全局变量;当函数体要正确地引入在类里定义的变量时,须使用self这个关键字。如self.name。
函数在模块下建议叫函数,函数在类里面建议叫方法; 变量在模块下建议叫变量,变量在类里面建议叫数据成员。
类和对象通过实例化建立联系。
- 类是现实世界或思维世界中的实体在计算机中的反映,它将数据以及这些数据上的操作封装在一起。类中的数据刻画对象的特征; 类中的方法刻画对象的行为
- 类就是一个模板,通过这个模板我们可以做出各种各样的对象。
构造函数:
1
2def __init__(self):
pass构造函数是自动调用的。调用函数的时候会自动调用构造函数。只能返回None,不能定义返回值。
构造函数的主要作用是初始化对象的属性、特性类变量和实例变量
类变量:和类相关联的变量
实例变量:和对象相关联的变量
self.xxx保存对象的特征值
self不能称之为关键字,可以定义为任意标识类与对象的变量查找顺序
- 对象中内置__dict__:以字典的方式返回对象中所有变量。调用方式:对象名.__dict__。
注:也可以访问类的__dict__,返回当前类的所有相关变量(类变量)。调用方式:类名.dict - 变量寻找机制:python会先在实例中查找 若实例中没有找到(__dict__中没有该变量)
python不会返回 会再去类中查找 类中找不到 会再到父类中查找
- 对象中内置__dict__:以字典的方式返回对象中所有变量。调用方式:对象名.__dict__。
self与实例方法
- self是指当前调用某一个方法的对象(self指的对象和类没有关系,谁调用了这个方法,它就指代谁),换句话说,self代表的是实例而不是类
- 实例方法最大的一个特点是:它的第一个参数是需要传入self
- 实例方法是和对象实例相关联的 ,也是实例可以调用的方法
- 实例方法访问实例变量:self.变量
- 实例方法方法访问类变量:
self.__class__.变量或者 类.变量
类方法
类方法定义:1
2
3@classmethod
def 方法名(cls):
pass注:@在python中叫装饰器,cls可为任意名字,但建议用cls
在类方法中调用类变量:cls.变量名 cls表示的是类本身
类外部调用类方法时,可以直接类名.类方法名(),也可以直接用实例名.类方法名(),但后者不推荐静态方法
- 静态方法前面要加上:@staticmethod
- 静态方法没有强制要求加上如self或cls等参数
- 静态方法可以被对象与类访问,即可以用 对象名.静态方法 与 类名.静态方法 的方式来访问静态方法
- 类方法和静态方法不能访问实例变量
- 能用静态方法的地方都可以用类方法代替,正常情况下不需要用静态方法
成员可见性
- 内部调用指在类的内部访问调用,外部调用指在类的外部访问调用,(成员)变量、方法等都有内部调用与外部调用
- 如果要对变量进行赋值,建议最好通过方法进行赋值,而不是直接更改变量值
因为变量只是一个固定的值,没有判断的功能,如果输入的值不符合要求,也无法进行错误提示
而定义一个方法进行赋值,则可以在该方法中设置判断语句,防止误输入不符合要求的值 - python默认类中的变量与方法是公开的,在之前加上__(双下划线)后认为是私有的,私有的变量、方法无法在类之外进行访问
- python语言是动态语言,可以在实例上直接添加变量
- 理论上讲,Python没有私有方法,没有什么不能访问,Python的私有方法为__,其实是实质为将变量的名称改变为 _类名__变量名
继承
子类对父类的继承:- 需要在定义子类时,用class 子类名(父类名)// from module import 父类
- 建议:一个模块只写一个类
- 子类可以继承父类的一切
- 子类里的构造函数里,如果要使用父类里的构造函数,可以调用
父类.__init__(self,必要的参数)(不推荐) - Python允许多继承,即一个子类可以有多个父类
- 用对象调用实例方法,不需要加self
- 而用类调用实例方法,则需要在前面加上self (没有意义)
- super关键字可以让子类调用父类的方法和变量,super的用法:super(子类名,self).调用的父类方法名
- 使用super的好处:更改父类的名称时,只要修改Student(Human)的名称即可,不需要逐条更改
- 若子类与父类出现同名方法,那么在调用对象时默认时使用子类的方法
正则表达式
定义
- 正则表达式是一个特殊的字符序列,一个字符串是否与我们所设定的字符序列相匹配,作用:实现快速检测文本、实现一些替换文本的操作
- 正则表达式模块re // re.findall(‘Python’,a) 以列表形式返回
- 正则表达式的灵魂是规则
- 正则表达式由一系列普通字符(如’Python’)和元字符(如’\d’)所组成
- \d匹配数字0-9 \D匹配非数字
字符集
- 字符集用中括号来找出需要的字符,括号两端的普通字符用于“定界”,括号内的字符是“或”关系
- 字符集匹配
1 | |
概括字符集
1 | |
数量词 {}
1.通常字符集[]只能匹配一个字符,要匹配多个字符都话可以在中括号后面加上{数字}或者{数字,数字},这样就可以匹配多个字符
2.要想匹配不定数量的字符可以用{数字,数字}这样的组合
贪婪与非贪婪
python默认为贪婪的匹配方式,即极可能多的匹配区间
如{3,6},python在匹配到3个字母时会继续向后匹配,直到不符合条件为止
如果想要以非贪婪运行,则在后面加上?即可,即{3,6}?
数量词 * + ?
1 | |
边界匹配符
边界匹配符:^和$
^指的是从开头开始匹配
$指的是从尾部开始匹配
组
组,使用()把一系列字符集合成一组。
[abc] 中括号内的各个字符是或关系,a 或 b 或 c
(abc) 小括号内的字符是且关系, abc三个字符一起出现
匹配模式参数
匹配模式参数(re.I,re.S)
- 匹配除\n以外的任意字符
- findall(pattern,str,模式参数),多个模式之间用 | 隔开
- 模式参数:re.I –>忽略字母的大小写,re.S–>匹配所有的字符,包括换行符
正则替换
正则替换:re.sub(pattern, repl, string, count=0, flags=0)
- pattern:正则表达式; repl:匹配成功后替换成的对象;string:我们搜索的原字符串; count:默认是等于0,表示全替换(=n时表示替换n个)
flags:模式参数。 - repl可以是常量,也可以是函数,当是函数时他的意义是正则表达式去string匹配,如果匹配到了传给函数的参数,此时还只是一个对象,如果想要从匹配的结果中拿到这个对象,可以用的方法是:(.group())。
- 补充知识:替换为常量的时候还可以用(.replace(pattern,repl))
- re.sub()函数:
把另外一个函数作为参数传入re.sub()函数
实现有条件的替换
传入的函数作为被传入函数的接口,以便实现更为复杂的要求
search与match函数
re模块中的其他方法:match()和search()
re.match():从字符串的首字符开始匹配,如果第一个不匹配,则返回None
re.search():搜索整个字符串,直到找到第一个满足正则表达式的结果,然后返回结果,否则为None
与findall的区别:
- findall返回结果为列表,match和search返回结果为对象(可用group()来读取结果,可用span()来返回结果在原字符串中的位置)
- match和search只匹配一次,无论成功与否,都会返回结果,findall返回所有的匹配结果
group分组
分组概念,可用来得到我们想要的中间值。
s = ‘life i use python, i python’
返回life和python之间的字符,也返回两个python之间的字符。方法一: r = re.search(‘life(.)python(.)python’, s)
print(r.group(0)) 整个结果
print(r.group(1)) 第一个分组
print(r.group(2)) 第二个分组
也可以用print(r.group(0,1,2)) #一行代码实现0、1、2三种返回,且返回结果是一个元祖
print(r.groups()) 只返回匹配的分组,不返回完整的结果。
方法二,可以用findall来实现:r = re.findall(‘life(.)python(.)python’, s) 返回是不用group,直接print(r),此时的r是一个list
JSON
定义
JSON:JavaScript Object Notation,JavaScript 对象标记
JSON本质:是一种轻量级的数据交换格式
- 轻量级是和XML作比较
- 数据交换格式:JSON是一种数据交换格式,它的载体是字符串(字符串是JSON的表现形式)
符合JSON格式的字符串叫做JSON字符串,如{‘name’: John}
JSON VS XML:JSON在互联网领域更受欢迎
JSON优势:易于阅读、解析,网络传输效率高,是一种跨语言交换数据(XML也是跨语言的)
反序列化
JSON具有两种数据结构
- object 对象 {}
- array 数组 []
反序列化:json是跨语言的,在不同语言解析成对应的数据结构
对于python:json.loads(json_str)
object转化为dict
array转化成list
序列化
json的数据类型和pytho转化
json | python
object dict
array list
string str
number int
number float
true Ture
false False
null None
序列化将python数据类型转换成JSON格式:json.dumps()
枚举
枚举定义
python所有枚举类型都是enum模块下Enum类的子类
使用方法:
1 | |
VIP.GREEN # 打印出的结果是VIP.GREEN而不是2,符合枚举的意义,枚举的意义重在标签,而不在数值
枚举优势
不用枚举的话有三种表示方式:
1 | |
缺点:
- 都为可变的,可在代码中更改值
- 没有防止相同标签的功能
注:类型确定下来之后是不应该被改变的
使用枚举类型可以解决以上缺点: - 枚举类型不能通过代码更改
- 枚举类型不允许有两个相同标签的类型出现
枚举 值 类型 名字
print(VIP.GREEN)返回VIP.GREEN,是枚举类型
print(VIP.GREEN.name)返回GREEN,是str类型
print(VIP.GREEN.value)返回2,是对应的值类型
枚举的比较运算
1.枚举类型之间可以进行等值比较(==),但直接和数值比较会返回False,如:
VIP.GREEN == 2 返回False
2.枚举类型之间不支持大小比较操作符(>、<)的.
3.枚举类型可以进行身份比较(is),如:
VIP.GREEN is VIP.GREEN 返回 True
4.不同枚举类中的枚举类型进行比较都会返回False。
枚举注意事项
枚举类中的不同枚举类型的值可以相同,此时这两个枚举类型中的第二个名称是第一个的别名,建议第二个命名为:第一个名称_ALIAS
若枚举类中存在别名,在遍历打印时只会打印出非别名的所有枚举类型。若想输出包括别名的所有枚举成员,有以下两种方法:
- 遍历:枚举类.members.items(),输出结果为元组(由标签名称、具体取值组成)
- 遍历:枚举类.__members__,输出为标签名称
枚举转换
枚举类型建议用数字来存储在数据库中,占据更少的存储空间,但不建议用数字来代表枚举类型(影响代码的可读性)
把数据库中存储的数字转换成枚举类型:枚举类名(数值)
闭包
闭包:概念晦涩,不建议从标准定义上来理解. 闭包和函数关系很大。
一切皆对象
函数在别的很多语言只是一段可执行的代码,并不是对象,因此也不能实例化。
也不能给函数赋值,而python可以,在python里一切皆对象。
函数可以作为一个函数的参数或者返回结果闭包的概念
闭包:由函数和它定义时的环境变量(函数外部的变量)组成。
闭包的一个现象:它的变量取值为它定义时的环境变量值,不能受后续外部变量影响。
闭包作为函数返回时会同时带上环境变量。可以用.__closure__查看,查看第一个变量值:.closure[0].cell_contents闭包注意事项
- 内部函数必须引用外部函数里定义的环境变量,如果在内部函数里定义了同名的变量,这个变量就会变成内部函数的局部变量,不在调用外部函数里的变量了,就不形成闭包了
- 需要在外部函数的末尾返回内部函数对象
- 检查一个闭包是否形成,可以在模块里调用外部函数,赋值给f,然后print(f.closure)
- 闭包vs非闭包
- 当在函数中尝试赋值给全局变量值时需要声明global,否则程序将认为它是局部变量
- 当一个函数内部出现: x = y时,系统会自动认为 = 号左边的变量为本地局部变量,将不在去找函数外部的变量值
global 变量名 :是把局部变量声明成全局变量
nonlocal 变量名 :强势申明此变量不是本地变量
闭包:很重要的一个作用是,有保存现场的一个功能,记住上一次被调用的状态
函数式编程
lambda表达式
匿名函数 (lambda表达式)
f = lambda x,y: x+y
r=f(1,2)
匿名函数的函数体 只能是一个表达式,不能是一个复杂的代码块
匿名函数没有函数名 且不用+return
三元表达式
其他语言: x>y?x:y
python语言:条件为真时返回的结果 if 条件判断 else 条件为假时的返回结果,例
r =x if x>y else y
匿名函数lambda适合用三元表达式,如
r=lambda x,y : x if x>y else y
map
map:是一个类class map,数学角度看就是映射,通常只是赋值给一个变量用
格式:map(func, iterables) 传入两个参数,func表示函数,iterables表示序列或者集合
使用场景:将会对它所传入的集合或者序列的每一项都执行传入的函数
map结合lambda表达式:
例:
list_x = [1,2,3,4,5,6,7,8]
list_y = [1,2,3,4,5,6,7,8]
map(lambda x, y: x*x + y, list_x, list_y)
注:
- lambda参数个数必须与传入map的列表个数保持一致;
- 结果输出列表的元素个数取决于元素个数较少的列表元素个数
reduce
reduce不在全局命名空间了,需要进行模块导入
- from functools import reduce
- 运算原理:连续计算,连续调用lambda表达式(即当lambda中有两个参数,而reduce传入的却自有一个参数,reduce会取前两个变量作为参数,算出的结果作为下次运算的第一个变量)
- reduce的第三个参数会作为初始值参与到lambda的计算当中
filter
filter(过滤器):过滤不需要的元素(可以理解为过滤掉布尔类型为False的元素)
格式:filter(function or None, iterable) (函数或空,序列)
返回结果是集合(与map类似),不像reduce返回的是一个数值,需要用list转换结果为列表
filter特点:lambda表达式返回结果必须是布尔值
filter靠返回结果来判断当前元素是否应该被保留在集合里,若为False,则从集合中剔除掉
命令式编程vs函数式编程
命令式编程: def if else for
函数式编程: map reduce filter 算子 lambda
函数式编程结合到命令式编程里,使代码简化,但不推荐全盘使用
装饰器
装饰器:在不修改代码逻辑的情况下,增加函数功能
编程的原则:对修改是封闭的,对拓展是开放的
方法1:原始方法
1 | |
缺点:没有采用开闭原则
方法2:采取开闭原则后,完成原函数的需求变更的一种方法:
1 | |
缺点:没有体现函数本身的特性
方法3:非语法糖的装饰器
实现装饰器要用到嵌套函数
装饰器最基本的特征:在外部函数的内部最终需要返回内部函数(类似于闭包,但没有环境变量)
1 | |
缺点:函数定义和调用都很复杂
方法4:语法糖的装饰器
@语法糖的作用和意义:
不修改原函数的基础上仍然能够用原函数名调用实现装饰后的新功能
装饰器可以理解为在原函数上添加 @符号后的函数名,添加新的功能。
接受定义函数时的复杂,但拒绝调用时的复杂。装饰器就可以在不改变原函数定义时,使原函数拥有新的功能。而且不改变函数调用方式和函数内部结构,一大特点。定义只写一次,但是调用却是到处都有。
1 | |
方法5:具有通用性的装饰器,不仅仅只和特定的函数绑定
1 | |
方法6:兼容具有关键字参数的函数
def wrapper(*args, **kw): #实现兼容各种参数的功能
1 | |
装饰器作用
- 提高代码稳定性:不需要改变原始功能块的代码,通过装饰器改变代码行为
- 提高代码复用性:装饰器代码块可复用性高
- 某一功能块可使用多个@装饰器